この記事について
AWS ManagedのElasticsearchでCustom PackageやUser Dictionaryが使用したかったので、試してみると通常のElasticsearchとの差異があったので気になり何が実行可能でなにが実行かのうでないのかをはっきさせたく検証を行いました。
ターゲット層はDocker等でElasticsearchを使用していてAWS ManagedのElasticsearchにMigrationしたいかたやまたあたらしくElasticsearchを使う方にも有益な情報だと思います。
Elasticsearchの準備
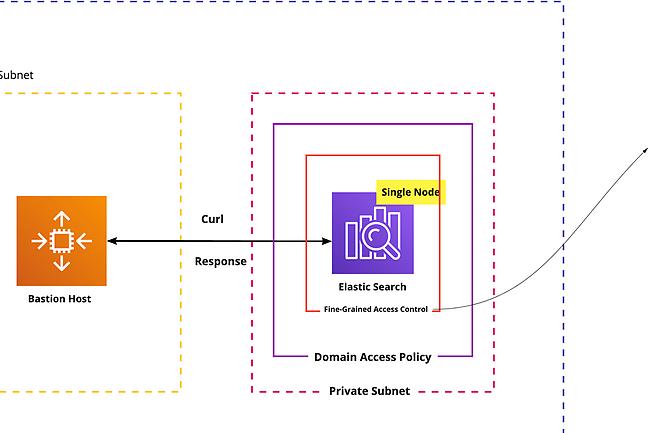
Elasticsearchを作成する際はVPC Optionを使ったり、Security Group, Domain Access Policy, Fine-Granted Access Controlでの制御が可能です。
サクッとためしたいだけであればPublicで作成しIP制限だけでもいいかと思います。
詳しくは以下のを参照していただけたらと思います。
Custom Packagesについて
AWS ManagedなElasticseachではCustom packagesが使用できます。Custom packagesではシノニム等のカスタム辞書ファイルをS3にUploadしClusterにAssociateすることで使用できます。
Elasticsearchに明示的に "タグバン", "Tagbangers", "タグバンガーズ"を同等に扱うように指示して検索結果を向上をすることができます。
1. S3に好きなファイルをUploadする。
synonym.txt
タグバンガーズ, タグバン, Tagbangers2. Import
ElasticsearchのPackageの画面に行き、Importを選択
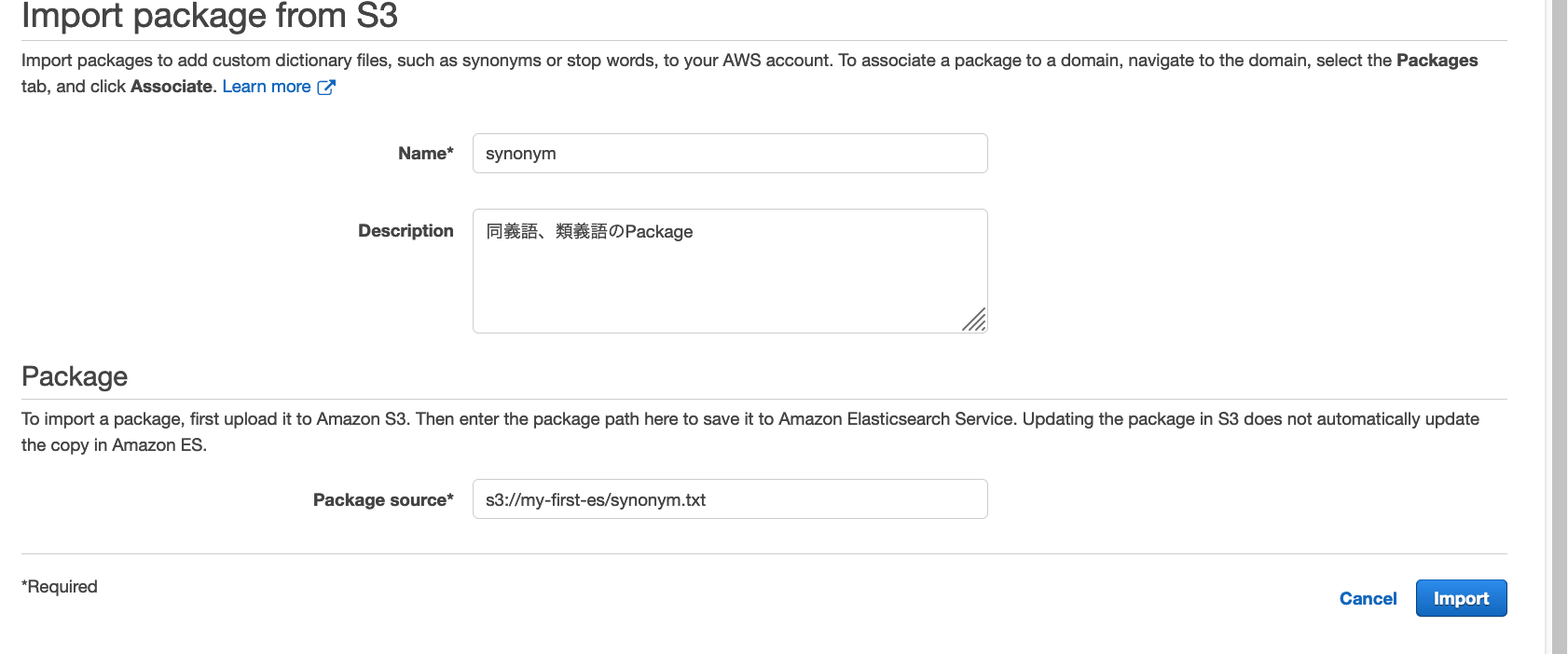
先程のs3のファイルのSource PathをPackage sourceに貼り付ける。
3. Associate
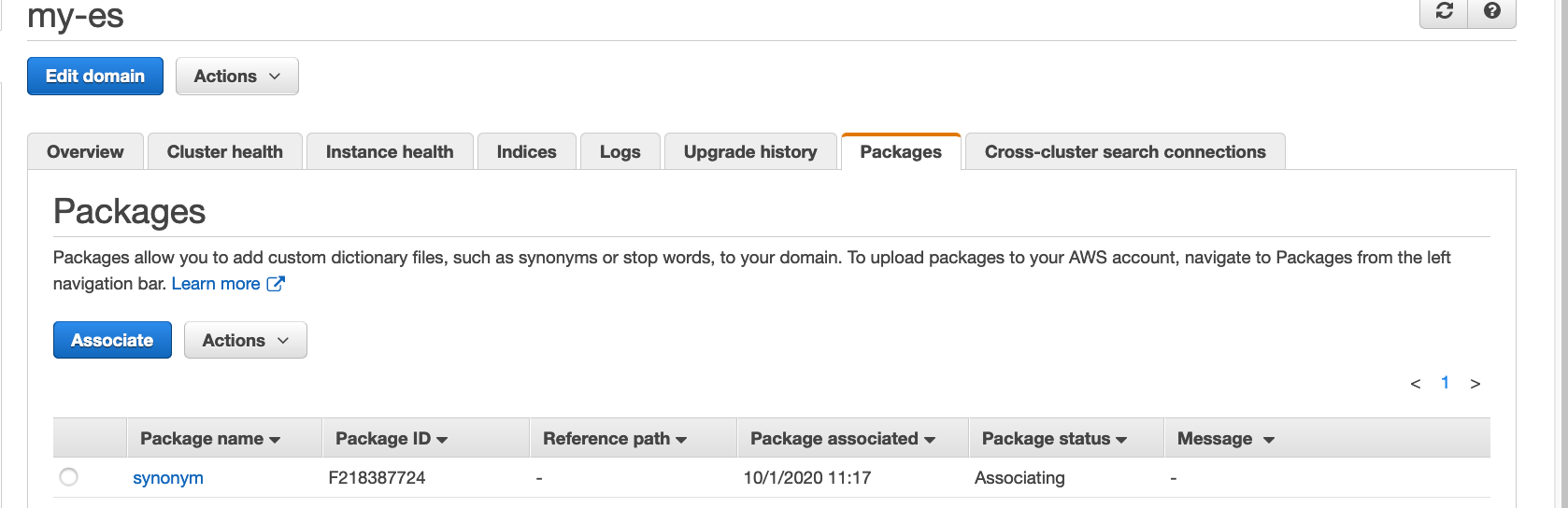
Elasticsearchの詳細画面に行き、Associateする。これでElasticsearch ClusterがS3のファイルを参照できるようになる。
ここでPackage IDが払い出されるのでメモしておきましょう。これでElasticSearchでFileをしようする準備ができました。
4. ElasticsearchにSynonymを登録
CurlやRest Clientとどちらでもいいので登録したいendpointにindexを作成しましょう。
PUT objects
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"japanese": {
"type": "custom",
"tokenizer": "kuromoji_tokenizer",
"filter": ["synonym_filter"]
}
},
"filter": {
"synonym_filter": {
"type": "synonym",
"synonyms_path": "<Package ID>"
}
}
}
}
},
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "japanese"
}
}
}
}上記のように特定のIndexにSynonymをToken Filter を登録する。
Package IDは先程、associateした際に払い出されたのを利用する。
これによりElasticsearchがS3のfileを参照することができる。
5. デモデータの投入 + 検証
投入
POST _bulk
{ "index": { "_index": "objects", "_id": "1" } }
{ "description": "タグバンガーズ" }
{ "index": { "_index": "objects", "_id": "2" } }
{ "description": "Tagbangers" }
{ "index": { "_index": "objects", "_id": "3" } }
{ "description": "タグバン" }検証
Request
GET objects/_search
{
"query": {
"match": {
"description": "タグバン"
}
}
}Response
"hits" : [
{
"_index" : "objects",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.44663,
"_source" : {
"description" : "タグバンガーズ"
}
}
]上記のようなResponseがかえってきます。
これでcustom packagesからsynonmが使用できることが確認できました。
Custom PackagesのUpdate方法
新しいバージョンのパッケージをにアップロードしても、Amazon S3 では Amazon Elasticsearch Service のパッケージは自動的に更新されません。
Amazon ES は独自のファイルのコピーを保存するため、新しいバージョンを S3 にアップロードする場合は、
ファイルを再度 Amazon ES にインポートし、ドメインに関連付ける必要があります。
つまりS3にあるtxt fileを変更して適応した場合どのようにするのかをみていきます。
結果としてS3は同期してくれないので、この場合はS3にtext fileをuploadして新規PackageをElasticsearchで作製して再び
associateしてElasticsearch内で新synonym fileを登録した、新indexを旧indexを新規indexにreindexする必要があります。
1. S3に新しいファイルをUploadする。
S3に好きな名前でファイルをuploadし先程と同じようにS3のpathを取得しておく。
今回は前回UploadしたFileに"TB"追加してUploadした
タグバンガーズ, タグバン, Tagbangers, TB2. 新ファイルをもとにPakcageをElasticsearchからImportしてAssociateする。
これも上記にあるのと同じステップを踏みassociateまで行います。
3. 新ファイルをもとにPakcageをElasticsearchからImportしてAssociateする。
先程つかったobjectsを使うのでなく新規のindexを作製します。
PUT neo-objects
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"japanese": {
"type": "custom",
"tokenizer": "kuromoji_tokenizer",
"filter": ["synonym_filter"]
}
},
"filter": {
"synonym_filter": {
"type": "synonym",
"synonyms_path": "<New Package ID>"
}
}
}
}
},
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "japanese"
}
}
}
}新規作製したPackageのIDをsynonyms_pathに入れます。
これで/neo-objectsではsynonymsとしてCustom Packageが登録されました。
4. Elasticsearchに旧indexを新indexにreindexする
いまのままでは新index (/neo-objects)ではなにもindexされないかつ、旧indexでは新しくUploadしたtxtが適応されていないので
### Reindex Previous Endpoint to new env
POST _reindex
{
"source": {
"index": "objects"
},
"dest": {
"index": "neo-objects"
}
}このようにします。これによりobjectsに登録されていたdocsが更新されたSynonymsをもつneo-objectsでindexされるようになります。
5. 検証
実際にTBが追加され正しく、searchされるのかを検証します。
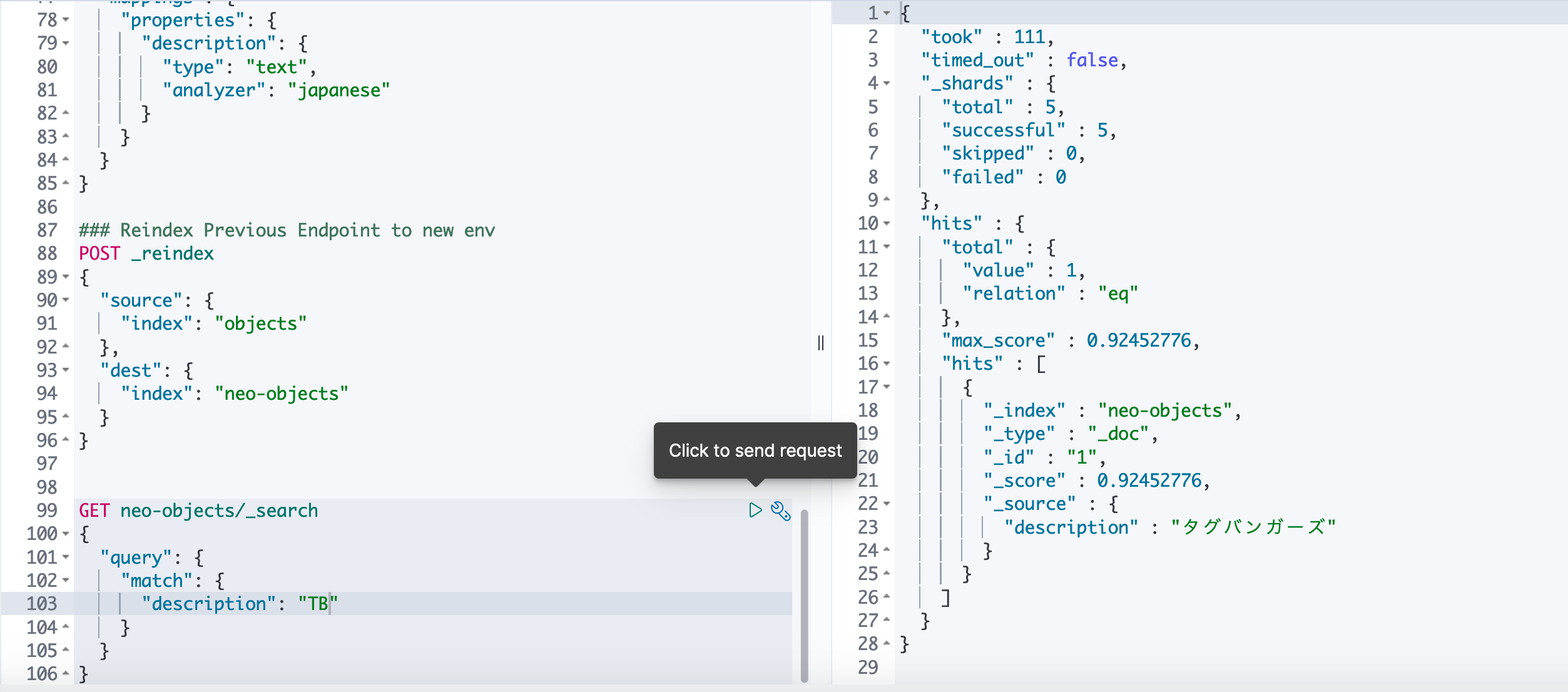
上記の選択部を実行すると右のようなResponseが返ってきます。これで正しくCustom Packageが登録されていることがわかります。
User Dictionaryについて
AWS公式によると、
The Kuromoji tokenizer uses the MeCab-IPADIC dictionary by default. A user_dictionary may be appended to the default dictionary. The dictionary should have the following CSV format:
ということなのでAWSでは公式にkuromojiのみuser_dictionaryをサポート。
特定の形式のcsvをuploadすることによりMeCab-IPADICを保管することができます。
せっかくだったので検証してみました。
検証
sample.txtを用意する。
リラックマ,リラックマ,リラックマ,カスタム名詞 妖怪たぬき合戦ポンポコ,妖怪たぬき合戦ポンポコ,妖怪たぬき合戦ポンポコ,カスタム名詞 きゃりーぱみゅぱみゅ,きゃりーぱみゅぱみゅ,きゃりーぱみゅぱみゅ,カスタム名詞 大根役者,大根役者,大根役者,カスタム名詞 なかやまきんにくん,なかやまきんにくん,なかやまきんにくん,カスタム名詞
これをESにAssociateした。
その後、すきなindexのsettigsから追加する。 (この際、ESから払い出されたPackage IDをメモしておく)
User Dictionaryの登録。
PUT daikon
{
"settings": {
"index":{
"analysis":{
"tokenizer" : {
"kuromoji_user_dict" : {
"type":"kuromoji_tokenizer",
"user_dictionary": "analyzers/F214458391"
}
},
"analyzer" : {
"my_analyzer" : {
"type" : "custom",
"tokenizer" : "kuromoji_user_dict"
}
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}analyzeしてみると、
GET daikon/_analyze
{
"analyzer": "my_analyzer",
"text": "なかやまきんにくん"
}GET Requestを送ると"見事になかやまきんにくん"が追加されていて単一名詞だと認識されている。
Analysis kuromoji 以外のPluginを設定したい場合
結論から言うとPluginそのものの置換はできない。
できることはkuromoji Pluginの拡張 (補完)としてUser DisctonaryをS3のファイルベースで追加する。
特定の言語 (英語以外)の形態解析を行う際にtoken filters, tokenizer等を設定する際に入れる。
日本語の公式としては Kuromojiのみサポートされている。AWS Mangedだと公式のみかつ最新版はサポートしていないので、Kuromoji以外は利用することはできない。
NeologdなどのAnalysis PluginはサポートされていないのでAWS MangedなElasticsearchでは利用できない。利用したい場合はContainerもしくはEC2等で独自にElasticsearchをHostingしてhttps://github.com/codelibs/elasticsearch-analysis-kuromoji-ipadic-neologdのようなモジュールを使う必要がある。
最後に
Neologdを辞書として使いたいというこえは多数あると思いますがAWS 公式としてはSupportをしていません。なので情報が少なくprojectで実際に仕様できるようなものは見つけられませんでした。以上のことからProjectで利用する際は独自でこのuser_dictionaryで補完分のカスタム名詞を作成してelasticsearchに登録する必要があると思います。