概要
この記事では、Elasticsearch Service を使用している Webアプリケーションにて発生した、Elasticsearch へのリクエストを完了できずタイムアウトする問題の原因を特定するために、CloudWatch Logs へスローログをパブリッシュするよう設定したことを紹介します。
問題
Web アプリケーションにて、データ照会画面や検索機能など、Elasticsearch Service へリクエストが発生する機能において、HTTP 502: Bad Gateway が発生しました。
Web アプリケーションログには、Elasticsearch への POST、または PUT リクエストのレスポンスが null であること、スタックトレースには TimeoutException が記録されていました。
解決方法
今回の問題が、特定のクエリに起因するものか、使用状況の変化に起因しているのかを判断するために、スローログを有効にしました。実施内容は 2点です。
- Elasticsearch のスローログレベルを変更
- CloudWatch Logs へスローログをパブリッシュするよう設定を有効化
設定の有効化は、AWS コンソールより Elasticsearch Service ダッシュボードにアクセスし、セットアップに従い設定しました。
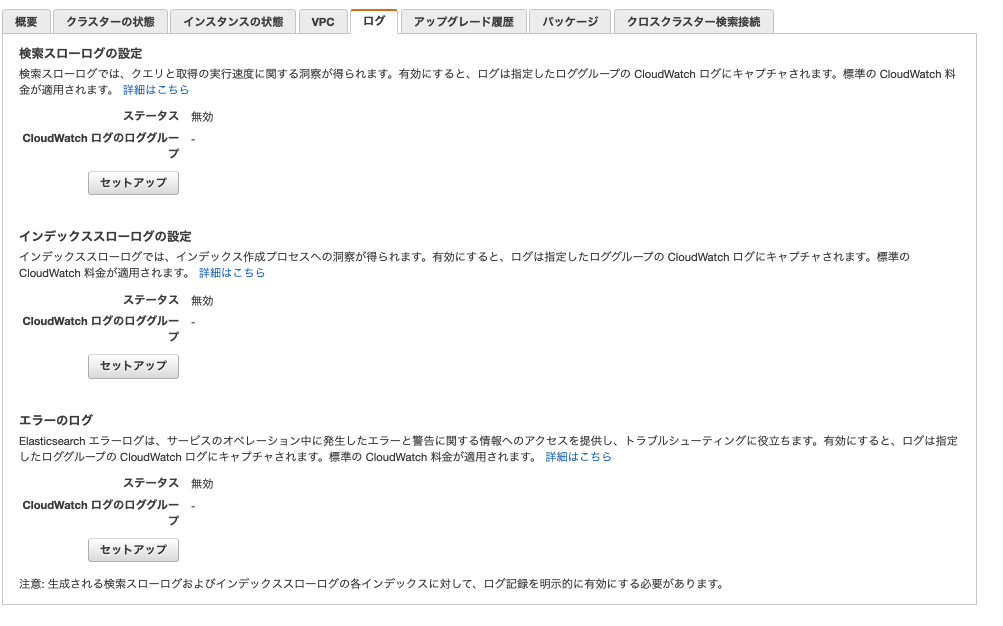

次に、Elasticsearch のスローログレベルを変更します。
Update index settings API を使用し、ログレベルとしきい値を設定しました。
しきい値のデフォルトは -1 のため、0以上を設定します。
curl -XPUT http://tagbangers-sample-2020.ap-northeast-1.es.amazonaws.com/index/_settings -d '{"index.search.slowlog.threshold.query.<level>":"10s"}'設定完了後、ロググループより考察し必要に応じてクエリの調整を行います。
備考
原因切り分けの調査として、検索パフォーマンスに影響する要因による可能性を、各種メトリクスにて確認したものの一部です。
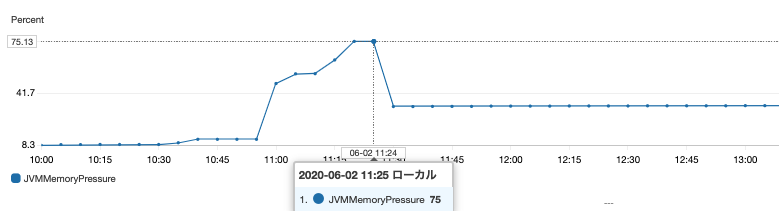
- JVM メモリ負荷
該当の時間に、JVMメモリ負荷が 75% の状態が 5分間発生していることを確認していますが、断続的なものではなく、
また、ガイドライン記載の推奨使用率 80% 以下をキープしています。 - リクエスト数のスパイク
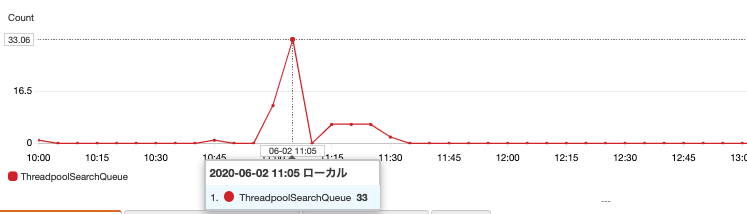
特筆点なし - 検索スレッドプールがもつ保留中のリクエスト数
急増が見られますが、断続的なものではありません。キューサイズ最大値は 1000 です。
参考
* Viewing Amazon Elasticsearch Service Slow Logs
* Monitoring Cluster Metrics with Amazon CloudWatch
* How do I troubleshoot high JVM memory pressure on my Amazon Elasticsearch Service cluster?